Appearance
SWB 附录 G:SGE 并行环境配置
来源:
swb_ug.pdfAppendix G(W-2024.09) 原文标题:Configuring Parallel Environments in SGE Scheduler说明:本页按 2024 版附录 G 的原顺序整理,尽量完整保留 SGE 并行环境的用途、推荐配置和添加步骤。
附录说明
本附录说明如何在 SGE 调度器中配置并行环境,以支持 SMP 和 MPI 作业运行。
它与 Chapter 11 的关系非常直接:Chapter 11 解释了 SWB 如何接入 SGE,而附录 G 则进一步解释,当提交并行作业时,SGE 这一侧应当如何准备并行环境。
并行环境
手册首先说明:向 SGE 调度器提交并行作业时,必须先在 SGE 侧配置并行环境。
Sentaurus Workbench 会利用 SGE 的并行环境,在提交并行作业时正确分配核心资源。原文特别区分了两类并行场景:
- 对于 SMP 作业,多线程进程所需的核心必须分配到同一台主机上
- 对于 MPI 作业,各个 worker 进程需要按照指定的“每主机进程数”分布进行分配;同时,每个 MPI worker 进程内部的线程也必须都运行在同一台主机上
与 LSF 的差异
手册强调,和 LSF 或其他调度器不同,SGE 中的并行环境并没有统一标准,不同站点可以按自己的方式命名和配置。
例如,Synopsys 内部的 Univa Grid Engine 集群会配置如下并行环境:
text
mt, dp, dp2, dp3, dp4, dp5, dp6, dp7, dp8, dp10, dp12, dp16, dp20,
dp24, dp32, dp40如果想查看当前 SGE 环境中可用的并行环境,手册给出的命令是:
bash
qconf -splSWB 对 MPI 资源分配的理解
手册说明,在提交 MPI 作业时,SWB 会根据以下几项信息自动安排 SGE 网格上的资源分配:
- MPI 进程数
- 每个 MPI 进程的线程数
- MPI 进程在主机之间的分布方式
默认名称与命名要求
手册提到,mt 和 dp 是推荐使用的默认名称,但你完全可以采用别的命名方案。
从 SWB 角度看,真正的要求只有一个:凡是用于分布式处理的并行环境,都必须共享同一个前缀。例如:
text
mpi_, mpi_2, mpi_4也就是说,名字本身可以变,但“同一类分布式并行环境要有可识别的统一前缀”这一点不能丢。
SWB 首选项中的默认并行环境名
手册还说明,你可以在 SWB Preferences 对话框中,把默认的 SGE 并行环境名称设置为 mt 和 dp。
如果你的 SGE farm 使用了别的名字,那么就必须把 SWB 的默认名称改成实际名称。
原文对应界面如下:
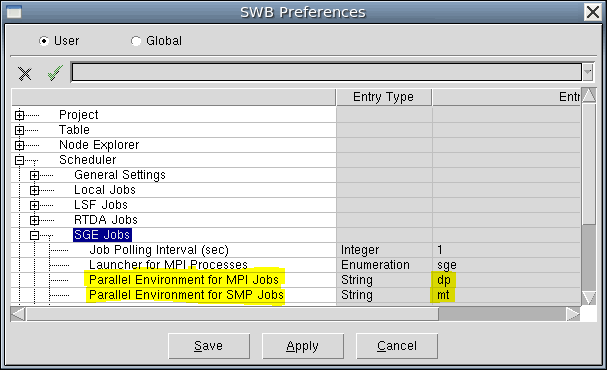
图 81:SWB Preferences 对话框中显示的默认 SGE 并行环境名称设置。
表 42:并行环境用途
| 并行环境名称 | 用途 | 提交示例 |
|---|---|---|
mt | 为多线程的 SMP 作业分配核心 | qsub -pe mt 4 ...:请求同一台主机上的 4 个核心 |
dp | 为 MPI 作业分配核心,适用于串行 MPI worker 进程,并采用默认的“每主机进程数”分布 | qsub -pe dp 4 ...:请求任意主机上的 4 个核心,由 SGE 自己决定如何分配。默认情况下,SGE 会尽量把核心集中到各个单独主机上,但实际行为仍取决于 SGE 配置。 |
dp<NN> | 为分布式 MPI 作业分配核心,适用于多线程 MPI worker 进程或需要指定“每主机进程数”分布的场景;其中 <NN> 为从 2 开始的数字 | qsub -pe dp4 64 ...:请求任意主机上的 64 个核心,但要求每 4 个核心必须位于同一主机。默认情况下,SGE 会尽量把每个 4 核块落到单独主机上。 |
基础 SGE 并行环境
手册接着给出推荐的基础 SGE 并行环境配置。
在进入具体配置之前,原文再次强调:如果你的 SGE farm 使用的是不同名称,那么你必须把默认名称替换成实际名称。
mt
手册给出的推荐配置如下:
text
pe_name mt
slots 9900000
user_lists NONE
xuser_lists NONE
start_proc_args NONE
stop_proc_args NONE
per_pe_task_prolog NONE
per_pe_task_epilog NONE
allocation_rule $pe_slots
control_slaves FALSE
job_is_first_task TRUE
urgency_slots min
accounting_summary FALSE
daemon_forks_slaves FALSE
master_forks_slaves TRUE从这一配置可以看出,mt 的核心特点是:通过 allocation_rule = $pe_slots,把所请求的核心集中分配到同一主机,以满足多线程 SMP 作业的需求。
dp
推荐配置如下:
text
pe_name dp
slots 999999
user_lists NONE
xuser_lists NONE
start_proc_args /bin/true
stop_proc_args /bin/true
per_pe_task_prolog NONE
per_pe_task_epilog NONE
allocation_rule $round_robin
control_slaves TRUE
job_is_first_task FALSE
urgency_slots min
accounting_summary FALSE
daemon_forks_slaves FALSE
master_forks_slaves FALSE这里最关键的点是:
allocation_rule = $round_robincontrol_slaves = TRUE
这说明 dp 的设计目标是分布式处理,而不是把所有核心收敛到单机。
dp2
手册随后给出 dp2 的配置:
text
pe_name dp2
slots 999
user_lists NONE
xuser_lists NONE
start_proc_args /bin/true
stop_proc_args /bin/true
per_pe_task_prolog NONE
per_pe_task_epilog NONE
allocation_rule 2
control_slaves TRUE
job_is_first_task TRUE
urgency_slots min
accounting_summary FALSE
daemon_forks_slaves FALSE
master_forks_slaves FALSEdp2 的核心变化在于:
pe_name改成dp2allocation_rule改成2
这表示每个分配块按 2 个核心聚合。
dp3
手册接着给出 dp3 的配置:
text
pe_name dp3
slots 999999
user_lists NONE
xuser_lists NONE
start_proc_args /bin/true
stop_proc_args /bin/true
per_pe_task_prolog NONE
per_pe_task_epilog NONE
allocation_rule 3
control_slaves TRUE
job_is_first_task TRUE
urgency_slots min
accounting_summary FALSE
daemon_forks_slaves FALSE
master_forks_slaves FALSE这里的逻辑与 dp2 相同,只是每个分配块改成了 3 个核心。
其他 dp 变体
手册明确说明,其他基于 dp 的并行环境与 dp2、dp3 类似,只需要在以下字段上做对应修改:
pe_nameallocation_rule
因此,如果你要扩展出 dp4、dp8、dp16 这类环境,本质上就是沿用同一模板,然后把这两个字段改成目标值。
向 SGE 集群添加并行环境
手册最后说明如何把这些并行环境真正加到 SGE farm 中。
管理员权限要求
原文先提醒:这些操作需要 SGE grid 的管理员权限。
添加步骤
要把一个并行环境加入 SGE farm,手册给出的步骤是:
把对应的并行环境设置保存到一个文件中。
使用下面命令把该并行环境加入 farm 配置:
bashqconf -Ap <filename>把创建好的并行环境加入到 farm 的队列定义中。
手册特别强调:你必须把这些并行环境加入到每个需要使用它们的队列的 pe_list 中。
对应命令为:
bash
qconf -mattr queue pe_list <pe_name> <queue_name>使用文本编辑器修改队列定义
附录还给出一种替代方式,就是直接打开队列定义文本进行修改:
bash
qconf -mq <queue_name>示例
手册示例:
bash
qconf -mattr queue pe_list dp2 all.q完成这些步骤后,就可以在 SGE farm 中使用对应的并行环境。
手册最后强调:对于你希望加入 SGE farm 的每一个并行环境,都必须重复执行上述步骤。
附录 G 的核心价值,是把“SWB 需要并行队列”进一步拆成“SMP 用什么环境、MPI 用什么环境、这些环境在 SGE 里应该怎样命名和挂到队列上”。如果后面继续细化,这一页最值得再补的一块,是把 mt、dp、dp<NN> 画成一张“核心分配方式”对照图。